
Di balik layar setiap aplikasi yang terasa cepat dan responsif, selalu ada satu ancaman senyap yang siap membuat sistem tersungkur kapan saja: resource contention. Memahami cara mengatasi resource contention menjadi keharusan bagi tim infrastruktur dan developer, terutama ketika trafik melonjak dan server mulai kehabisan napas. Tanpa strategi yang jelas, gejalanya akan muncul pelan pelan, dari latency meningkat, error 500 bermunculan, hingga akhirnya server benar benar down di jam paling sibuk.
Mengapa Resource Contention Bisa Membunuh Server Tanpa Peringatan
Sebelum melangkah ke cara mengatasi resource contention secara teknis, penting memahami dulu bagaimana masalah ini muncul. Resource contention terjadi ketika beberapa proses atau thread berebut sumber daya yang sama pada saat bersamaan. Sumber daya ini bisa berupa CPU, memori, disk I O, koneksi database, hingga lock pada tabel atau row.
Dalam banyak kasus di lingkungan produksi, masalah ini tidak muncul secara tiba tiba. Ia berawal dari desain arsitektur yang kurang efisien, query database yang berat, kode yang tidak optimal, dan pola penggunaan yang berubah seiring bertambahnya pengguna. Kombinasi faktor faktor ini membuat server bekerja di ambang batas, lalu kolaps ketika ada sedikit lonjakan beban.
> “Gangguan terbesar di sistem produksi jarang berasal dari satu bug besar, melainkan dari akumulasi keputusan kecil yang dibiarkan tanpa pengawasan.”
Ketika resource contention dibiarkan, server akan mulai menunjukkan gejala seperti antrean request yang mengular, throughput turun drastis, dan waktu respons yang melonjak berkali lipat. Di titik ini, penanganan tidak cukup hanya dengan menambah server; akar masalahnya harus diurai.
Mengenali Gejala Awal Sebelum Terlambat
Menguasai cara mengatasi resource contention juga berarti piawai membaca tanda tanda awalnya. Tanpa pemantauan yang tepat, tim sering kali baru sadar ketika pengguna sudah mengeluh.
Gejala Teknis yang Sering Diabaikan dalam Cara Mengatasi Resource Contention
Ada beberapa indikator teknis yang hampir selalu muncul ketika terjadi resource contention, namun kerap dianggap “normal” karena tidak langsung menyebabkan error fatal.
Pertama, CPU usage yang sering menyentuh 90 hingga 100 persen dalam durasi panjang. Bukan sekadar spike singkat, melainkan plateau yang bertahan beberapa menit atau jam. Ini menandakan terlalu banyak proses yang berebut siklus CPU, sering kali akibat loop berat, query tidak efisien, atau thread yang tidak pernah idle.
Kedua, memori yang terus meningkat tanpa pernah turun signifikan. Jika pola ini terjadi, bisa jadi ada memory leak atau proses yang tidak pernah melepaskan resource. Ketika memori hampir habis, sistem akan mulai melakukan swapping ke disk, membuat kinerja turun drastis dan memperparah resource contention di lapisan I O.
Ketiga, antrean request di web server atau message queue yang terus menumpuk. Misalnya, antrean job di RabbitMQ atau Kafka yang tidak pernah berkurang, padahal konsumer tetap berjalan. Ini indikasi jelas bahwa kapasitas pemrosesan tidak sebanding dengan beban masuk, entah karena bottleneck di CPU, database, atau service hilir.
Keempat, peningkatan tajam waktu eksekusi query database. Query yang biasanya selesai dalam 50 milidetik tiba tiba menjadi 500 milidetik atau beberapa detik. Ini sering berkaitan dengan lock di tabel, full table scan, atau index yang tidak optimal.
Terakhir, munculnya error terkait timeout dan connection pool, seperti “timeout acquiring connection from pool” atau “lock wait timeout exceeded”. Ini sinyal bahwa resource di layer database atau service lain sedang diperebutkan terlalu banyak klien.
Menguatkan Observabilitas Sebelum Mengutak Atik Konfigurasi
Banyak tim langsung mengubah konfigurasi server atau menambah instance ketika terjadi gangguan. Padahal, cara mengatasi resource contention yang efektif selalu dimulai dari visibilitas yang baik terhadap sistem.
Membangun Dasar Observasi untuk Cara Mengatasi Resource Contention
Langkah pertama adalah memastikan metrik utama dikumpulkan dan dipantau secara konsisten. Metrik yang penting antara lain CPU usage per core, penggunaan memori, I O disk, latency per endpoint, error rate, antrean request, dan metrik spesifik database seperti jumlah koneksi aktif, lock, serta query paling lambat.
Gunakan tool monitoring terpusat seperti Prometheus dengan Grafana, New Relic, Datadog, atau solusi sejenis untuk memvisualisasikan tren. Yang tidak kalah penting, buat alert yang cerdas, bukan sekadar alarm setiap CPU menyentuh 80 persen. Alert sebaiknya mempertimbangkan durasi, tren, dan kombinasi metrik, misalnya CPU tinggi bersamaan dengan latency dan error rate yang meningkat.
Tracing terdistribusi juga berperan besar. Dengan tracing, tim dapat melihat jalur lengkap sebuah request melintasi microservice, database, dan external API. Di sini akan terlihat titik mana yang paling lambat dan sering menjadi sumber resource contention. Alat seperti Jaeger, Zipkin, atau OpenTelemetry dapat membantu membangun gambaran menyeluruh.
Log yang terstruktur dan dapat dicari dengan mudah juga wajib. Sistem seperti ELK Stack atau Loki memudahkan korelasi antara lonjakan metrik dan event spesifik di aplikasi. Tanpa observabilitas yang matang, upaya mengatasi resource contention hanya akan menjadi tebak tebakkan mahal.
Mengoptimalkan Kode Aplikasi yang Menjadi Sumber Bottleneck
Setelah sumber masalah mulai teridentifikasi, fokus berikutnya adalah aplikasi itu sendiri. Banyak kasus resource contention bersumber dari pola pemrograman yang tidak efisien, bukan semata keterbatasan hardware.
Pola Penguncian dan Multithreading dalam Cara Mengatasi Resource Contention
Dalam aplikasi yang menggunakan multithreading, penggunaan lock yang tidak hati hati dapat memicu deadlock atau kontensi berat. Misalnya, penggunaan global lock untuk melindungi struktur data bersama, padahal sebagian besar operasi hanya perlu read. Solusinya adalah menerapkan lock yang lebih granular, atau menggunakan read write lock yang memungkinkan banyak pembaca berjalan paralel.
Selain itu, hindari critical section yang terlalu panjang. Semakin lama sebuah thread memegang lock, semakin besar peluang thread lain harus menunggu. Refactoring kode untuk meminimalkan pekerjaan di dalam blok yang dilindungi lock adalah salah satu cara mengatasi resource contention yang sering diabaikan.
Di sisi lain, asynchronous programming dapat membantu mengurangi jumlah thread yang dibutuhkan. Alih alih membuat ratusan thread yang semuanya menunggu I O, gunakan event loop dan non blocking I O agar satu thread bisa menangani banyak koneksi. Pendekatan ini telah terbukti efektif di banyak web server modern.
Menjinakkan Database yang Sering Menjadi Titik Paling Lemah
Tidak berlebihan jika dikatakan bahwa sebagian besar masalah performa di sistem skala menengah hingga besar berakar di database. Karena itu, cara mengatasi resource contention hampir selalu menyentuh lapisan ini.
Strategi Query dan Index dalam Cara Mengatasi Resource Contention
Mulailah dengan mengidentifikasi query yang paling sering dijalankan dan yang paling lambat. Hampir semua database modern menyediakan fitur untuk melihat slow query log atau execution plan. Dari sini, bisa terlihat apakah ada full table scan, join yang berat, atau penggunaan fungsi yang menghalangi pemanfaatan index.
Optimasi bisa dilakukan dengan menambahkan index yang tepat, memecah query menjadi lebih kecil, atau menghindari operasi yang memaksa lock besar seperti update masal pada tabel utama di jam sibuk. Denormalisasi terkontrol juga layak dipertimbangkan ketika beban baca jauh lebih besar daripada tulis.
Penggunaan connection pool yang sehat juga krusial. Terlalu sedikit koneksi membuat request mengantre, terlalu banyak koneksi justru menambah beban database dan memicu resource contention internal. Konfigurasi jumlah koneksi ideal perlu diuji berdasarkan kapasitas server database dan pola trafik aplikasi.
> “Skalabilitas jarang tercapai hanya dengan menambah server. Sering kali, satu query yang dirombak bisa menghemat lebih banyak resource daripada satu cluster baru.”
Mengatur Ulang Arsitektur untuk Mengurangi Beban Terpusat
Ketika aplikasi dan database sudah dioptimalkan, namun beban terus tumbuh, saatnya melihat arsitektur secara keseluruhan. Di sinilah cara mengatasi resource contention menyentuh keputusan desain di level sistem.
Pemisahan Layanan dan Skala Horizontal dalam Cara Mengatasi Resource Contention
Monolit besar dengan satu database tunggal cenderung menciptakan titik kontensi yang sulit dipecah. Memisahkan layanan berdasarkan domain fungsional dapat membantu menyebarkan beban. Misalnya, memisahkan layanan autentikasi, pembayaran, dan katalog produk ke service terpisah, masing masing dengan resource sendiri.
Skala horizontal juga harus dipertimbangkan secara serius. Menambah instance aplikasi di belakang load balancer dapat menyebarkan beban CPU dan memori. Namun, ini hanya efektif jika lapisan di bawahnya, terutama database dan cache, juga siap menangani beban lebih besar.
Penerapan cache di berbagai lapisan dapat mengurangi tekanan pada resource utama. Cache di sisi aplikasi, Redis atau Memcached sebagai cache terdistribusi, hingga cache hasil query yang sering dipakai, semuanya berkontribusi mengurangi resource contention di database dan service hilir.
Message queue juga dapat digunakan untuk mengubah proses sinkron yang berat menjadi proses asinkron. Misalnya, mengalihkan pengiriman email, pemrosesan gambar, atau perhitungan laporan ke job di background. Dengan begitu, request utama ke pengguna tetap ringan dan cepat.
Menyusun Prosedur Operasional Saat Lonjakan Terjadi
Tidak ada sistem yang bebas masalah selamanya. Bahkan dengan semua optimasi, lonjakan trafik tak terduga atau bug baru bisa kembali memicu resource contention. Karena itu, cara mengatasi resource contention juga harus dituangkan dalam prosedur operasional yang jelas.
Tim perlu memiliki runbook yang berisi langkah langkah konkret ketika metrik tertentu melewati ambang batas. Misalnya, apa yang harus dilakukan ketika CPU di atas 90 persen selama 10 menit, atau ketika antrean job menumpuk lebih dari jumlah tertentu. Langkah ini bisa berupa scale out otomatis, penonaktifan fitur non esensial, atau pengalihan sebagian trafik.
Simulasi insiden secara berkala juga membantu tim lebih sigap. Dengan chaos testing atau load testing terencana, titik lemah baru bisa ditemukan sebelum menjadi masalah nyata di produksi. Dari setiap insiden, dokumentasi dan perbaikan jangka panjang harus menjadi bagian dari budaya kerja, bukan sekadar pemadaman kebakaran sesaat.
Pada akhirnya, menguasai cara mengatasi resource contention bukan hanya soal menjaga server tetap hidup, tetapi juga tentang membangun sistem yang tangguh, terukur, dan siap tumbuh bersama kebutuhan bisnis yang terus meningkat.
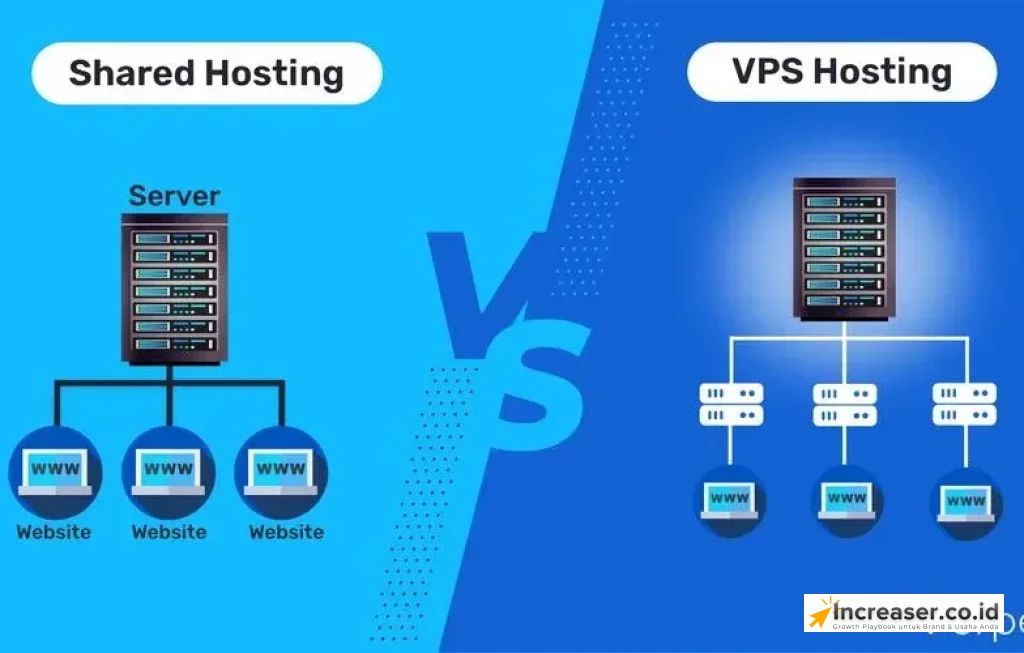
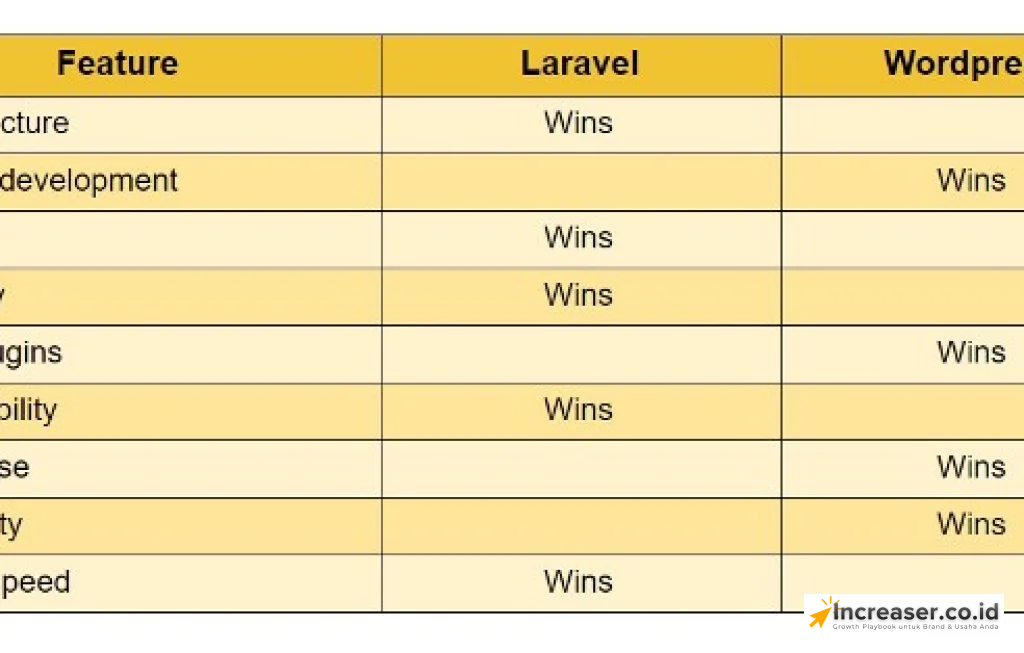








Comment