
Dalam ekosistem mesin pencari modern, memahami webcrawler dalam SEO bukan lagi pilihan, tetapi kebutuhan. Di balik setiap halaman yang muncul di hasil pencarian, ada proses panjang mulai dari perayapan, pengindeksan, hingga penilaian kualitas. Semua itu dimulai dari satu aktor utama yang sering tidak terlihat: webcrawler. Tanpa kerja webcrawler, konten terbaik sekalipun bisa tenggelam dan tidak pernah ditemukan pengguna.
Mengapa Webcrawler dalam SEO Menentukan Nasib Halaman Anda
Sebelum berbicara soal trik dan strategi, penting memahami mengapa webcrawler dalam SEO menjadi titik awal perjalanan sebuah halaman. Mesin pencari seperti Google, Bing, atau yang lain tidak “melihat” internet secara langsung. Mereka mengandalkan robot otomatis untuk mengunjungi, membaca, dan menyimpan informasi dari setiap halaman yang bisa dijangkau.
Webcrawler berfungsi sebagai mata dan telinga mesin pencari. Ia menentukan halaman mana yang layak dikunjungi, seberapa sering harus kembali, serta bagian mana yang penting untuk disimpan di indeks. Jika struktur situs berantakan, tautan internal lemah, atau ada banyak hambatan teknis, webcrawler akan kesulitan melakukan tugasnya. Akibatnya, halaman bisa terlambat terindeks, bahkan sama sekali tidak muncul di hasil pencarian.
“Banyak pemilik situs sibuk memikirkan kata kunci, tapi lupa bahwa tanpa webcrawler yang bisa bekerja lancar, semua optimasi itu hanya akan berhenti di dalam server mereka sendiri.”
Cara Kerja Webcrawler dalam SEO dari Awal hingga Terindeks
Untuk memahami posisi webcrawler dalam SEO, perlu melihat prosesnya secara berurutan. Mesin pencari tidak hanya merayapi secara acak, melainkan mengikuti alur yang cukup sistematis. Dari sudut pandang teknis, ada tiga tahap besar: penemuan URL, perayapan, dan pengindeksan.
Tahap Penemuan URL oleh Webcrawler dalam SEO
Pada tahap pertama, webcrawler dalam SEO harus menemukan dulu alamat halaman yang akan dikunjungi. Mesin pencari tidak serta merta tahu semua URL di internet. Ada beberapa sumber penemuan URL yang utama.
Pertama, sitemap XML yang Anda kirimkan melalui Google Search Console atau alat serupa. Sitemap berfungsi sebagai daftar isi resmi situs Anda. Di sini, Anda memberi tahu mesin pencari halaman mana yang penting, kapan terakhir diperbarui, dan seberapa sering berubah.
Kedua, tautan internal dan eksternal. Webcrawler bergerak dengan mengikuti link dari satu halaman ke halaman lain. Jika sebuah halaman tidak memiliki tautan yang mengarah kepadanya, halaman tersebut berpotensi menjadi “orphan page” yang sulit ditemukan crawler. Begitu juga dengan tautan dari situs lain yang mengarah ke situs Anda, yang membantu mesin pencari menemukan domain baru atau halaman baru.
Ketiga, database internal mesin pencari. Mereka menyimpan daftar URL lama yang pernah dikunjungi dan menjadwalkan ulang kunjungan berdasarkan prioritas, otoritas situs, serta frekuensi pembaruan.
Proses Perayapan: Apa yang Dilihat Webcrawler dalam SEO
Setelah menemukan URL, webcrawler dalam SEO mulai melakukan perayapan. Pada tahap ini, robot mengunjungi halaman dan membaca seluruh konten yang bisa diakses, mulai dari HTML, teks, gambar, hingga data terstruktur.
Webcrawler tidak membaca halaman seperti manusia. Ia memindai kode sumber dan mencari elemen penting seperti judul halaman, heading, meta description, teks utama, alt text gambar, serta tautan yang ada di dalamnya. Kecepatan dan kedalaman perayapan sangat dipengaruhi oleh kualitas server, waktu muat halaman, serta struktur HTML.
Jika halaman terlalu berat, banyak skrip yang menghambat, atau sering error, crawler bisa menghentikan proses sebelum selesai. Inilah yang kemudian dikenal sebagai masalah crawl budget, ketika mesin pencari hanya mau menghabiskan waktu terbatas di situs yang dianggap kurang efisien.
Pengindeksan: Bagaimana Informasi Disimpan Mesin Pencari
Setelah webcrawler dalam SEO selesai membaca sebuah halaman, langkah berikutnya adalah pengindeksan. Di sini, mesin pencari memutuskan apakah konten halaman tersebut layak dimasukkan ke dalam indeks mereka. Indeks ini ibarat perpustakaan raksasa yang akan menjadi sumber jawaban ketika pengguna mengetikkan kata kunci.
Dalam proses pengindeksan, mesin pencari mencoba memahami topik utama halaman, menilai relevansi kata kunci, melihat struktur konten, serta menilai berbagai sinyal kualitas lainnya. Tidak semua halaman yang dirayapi akan diindeks. Halaman dengan konten duplikat, sangat tipis, atau dianggap tidak bermanfaat bisa saja diabaikan.
Peran Webcrawler dalam SEO Teknis di Balik Layar
Banyak aspek SEO teknis secara langsung berkaitan dengan cara webcrawler dalam SEO bekerja. Setiap pengaturan di server, setiap baris kode di file konfigurasi, hingga struktur URL, semuanya bisa mempermudah atau justru menghalangi perayapan.
Robots.txt dan Cara Mengarahkan Webcrawler dalam SEO
Salah satu alat utama untuk mengontrol pergerakan webcrawler dalam SEO adalah file robots.txt. File ini ditempatkan di root domain dan berisi instruksi sederhana: bagian mana dari situs yang boleh atau tidak boleh dirayapi.
Dengan robots.txt, Anda bisa memblokir direktori sensitif, halaman admin, atau halaman yang tidak ingin muncul di hasil pencarian. Namun kesalahan konfigurasi di sini bisa fatal. Banyak kasus situs hilang dari hasil pencarian hanya karena satu baris perintah yang salah, misalnya memblokir seluruh direktori utama.
Penting juga memahami bahwa robots.txt hanya memberi tahu crawler apa yang boleh diakses, bukan apa yang boleh diindeks. Untuk mengontrol pengindeksan, diperlukan meta tag khusus seperti noindex atau pengaturan di header HTTP.
Crawl Budget: Kuota Perhatian Webcrawler dalam SEO
Setiap situs memiliki apa yang sering disebut sebagai crawl budget, yaitu jumlah halaman yang bersedia dirayapi mesin pencari dalam periode tertentu. Situs besar dengan ratusan ribu halaman sangat bergantung pada efisiensi penggunaan crawl budget ini.
Webcrawler dalam SEO akan menilai seberapa cepat server merespons, seberapa sering konten berubah, serta seberapa penting situs tersebut secara keseluruhan. Jika server lambat atau sering error, crawler bisa mengurangi frekuensi kunjungan. Di sisi lain, situs dengan struktur bersih dan konten berkualitas akan cenderung mendapatkan perhatian lebih.
Mengoptimalkan crawl budget berarti mengurangi halaman tidak penting, menghindari duplikasi konten, memperbaiki tautan rusak, serta memastikan sitemap hanya berisi URL yang benar benar layak dirayapi.
Strategi Mengoptimalkan Webcrawler dalam SEO di Situs Anda
Setelah memahami cara kerja dasar, langkah berikutnya adalah mengoptimalkan situs agar lebih bersahabat bagi webcrawler dalam SEO. Strategi ini tidak hanya teknis, tetapi juga menyentuh aspek struktur informasi dan kualitas konten.
Struktur Tautan Internal yang Ramah Webcrawler dalam SEO
Tautan internal adalah peta jalan bagi webcrawler dalam SEO. Semakin jelas dan teratur peta tersebut, semakin mudah robot menjelajahi seluruh isi situs. Struktur yang baik biasanya berbentuk hierarki yang logis, dari halaman beranda ke kategori, lalu ke halaman konten yang lebih spesifik.
Setiap halaman penting sebaiknya bisa dijangkau dalam beberapa klik dari beranda. Hindari membuat halaman yang hanya bisa diakses melalui pencarian internal atau interaksi khusus yang tidak terbaca crawler. Gunakan anchor text yang deskriptif agar mesin pencari memahami hubungan antarhalaman.
Breadcrumb, menu navigasi yang konsisten, dan daftar artikel terkait juga membantu memperkuat jaringan tautan internal. Semua ini membuat crawler tidak tersesat dan bisa menemukan halaman baru dengan cepat setiap kali datang.
Kecepatan Situs dan Pengaruhnya pada Webcrawler dalam SEO
Kecepatan situs bukan hanya faktor kenyamanan pengguna, tetapi juga memengaruhi kinerja webcrawler dalam SEO. Halaman yang lambat membuat crawler menghabiskan lebih banyak waktu untuk memuat setiap URL, sehingga jumlah halaman yang bisa dijelajahi dalam satu sesi menjadi berkurang.
Optimasi kecepatan dapat dilakukan dengan kompresi gambar, penggunaan caching, minimifikasi CSS dan JavaScript, serta pemilihan server yang andal. Penggunaan teknologi seperti lazy load perlu diatur hati hati agar tidak menghambat elemen penting yang perlu dibaca crawler.
Selain itu, peralihan ke protokol HTTPS yang aman juga menjadi sinyal positif. Mesin pencari cenderung lebih memprioritaskan situs yang aman dan stabil, yang pada akhirnya memengaruhi seberapa sering crawler berkunjung.
Webcrawler dalam SEO dan Kualitas Konten di Mata Mesin Pencari
Banyak orang mengira webcrawler hanya peduli pada aspek teknis, padahal kualitas konten juga sangat berpengaruh. Cara konten disusun, seberapa jelas struktur penulisannya, hingga bagaimana informasi disajikan, semuanya dibaca dan dinilai oleh mesin pencari.
Cara Webcrawler dalam SEO Menilai Halaman Berkualitas
Saat merayapi halaman, webcrawler dalam SEO mengumpulkan berbagai sinyal yang kemudian digunakan algoritma untuk menilai kualitas. Struktur heading yang rapi, paragraf yang mudah dibaca, penggunaan kata kunci yang wajar, serta keberadaan data terstruktur menjadi indikator penting.
Konten yang memberikan jawaban jelas terhadap suatu topik, didukung referensi, dan tidak sekadar berputar putar di seputar kata kunci, cenderung mendapatkan penilaian lebih baik. Mesin pencari terus mengembangkan kemampuan mereka untuk membedakan konten informatif dengan konten yang hanya diisi kata kunci tanpa nilai.
Penggunaan markup schema juga membantu webcrawler memahami elemen khusus di halaman, seperti artikel berita, produk, ulasan, atau FAQ. Informasi tambahan ini dapat meningkatkan peluang muncul dengan tampilan yang lebih menonjol di hasil pencarian.
“Pada akhirnya, webcrawler hanyalah perantara. Yang mereka cari bukan sekadar halaman yang bisa dirayapi, tetapi halaman yang pantas direkomendasikan kepada jutaan pengguna.”
Menghindari Perangkap yang Menyulitkan Webcrawler dalam SEO
Ada sejumlah praktik yang tanpa disadari membuat webcrawler dalam SEO kesulitan. Misalnya, penggunaan JavaScript berlebihan yang memuat konten utama hanya setelah interaksi tertentu, atau navigasi yang sepenuhnya bergantung pada elemen yang tidak terbaca crawler.
Konten duplikat di banyak URL berbeda juga membuat crawler membuang waktu pada halaman yang sama. Parameter URL yang tidak dikendalikan, filter yang menghasilkan banyak kombinasi halaman serupa, serta halaman tipis tanpa nilai tambah, semuanya menggerus efisiensi perayapan.
Menggunakan alat seperti Google Search Console, log server, dan audit SEO teknis dapat membantu mengidentifikasi masalah ini. Dari sana, pemilik situs bisa mengambil langkah konkret seperti menerapkan kanonikal, mengatur parameter, atau menggabungkan halaman yang terlalu mirip.
Hubungan Webcrawler dalam SEO dengan Perubahan Algoritma
Mesin pencari terus mengembangkan algoritma mereka untuk memberikan hasil yang lebih relevan dan aman. Setiap perubahan algoritma biasanya juga diiringi penyesuaian cara webcrawler dalam SEO bekerja, baik dari sisi prioritas perayapan maupun cara memahami konten.
Ketika mesin pencari memberi bobot lebih besar pada pengalaman pengguna, misalnya, webcrawler akan lebih memperhatikan sinyal teknis seperti kecepatan, stabilitas tampilan di perangkat mobile, dan struktur halaman. Begitu pula ketika mereka memerangi spam, crawler akan lebih jeli mendeteksi pola tautan tidak wajar atau konten otomatis berkualitas rendah.
Karena itu, memahami webcrawler bukan sekadar belajar teknis sekali lalu selesai. Ini menjadi proses berkelanjutan mengikuti perkembangan mesin pencari. Situs yang responsif terhadap perubahan ini akan lebih mudah menjaga visibilitasnya, sementara yang mengabaikannya berisiko tertinggal di belakang pesaing.

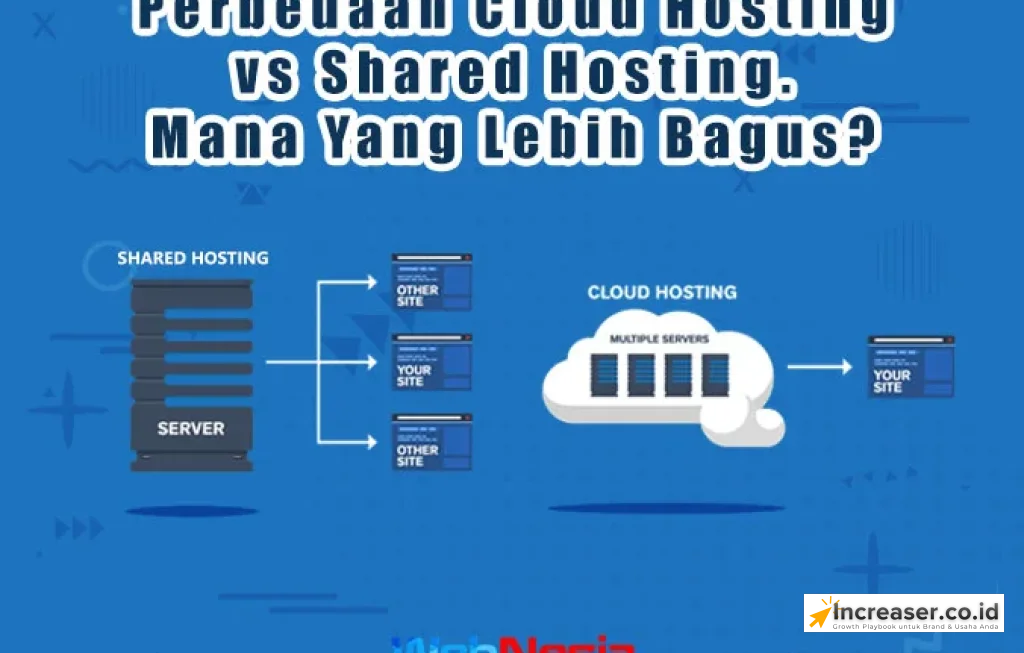










Comment